
Database Indexing
A database index is a data structure that improves the speed of data retrieval operations on a database table at the cost of additional writes and the use of more storage space to maintain the extra copy of data.
It enhances the speed of accessing the data by minimizing the disk access required each time when a query is processed. The lookup is much faster using the indexes which point to the address of the location where the required data can be found.
Structure of an Index

The above image shows the structure of an index in the database.
The first column ‘Key’ contains the copy of the Primary key or Candidate Key. These values are stored in sorted order to make the searching easier.
The second column ‘Data Reference’ contains the set of pointers holding the address of the blocks in the disk where the searched data can be found.
Types of Indexing
Primary Index
In this type of indexing, the primary key of the database table is used to create the index. They are stored in sorted order to make the searching faster. As the primary key contains unique values, it makes the searching very efficient and overall enhances the performance.
It can further be classified into two types.
1. Dense Index - Dense Index contains an index record for every key value in the data file. It fastens the searching speed but consumes more space to store index records.
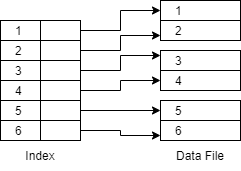
As shown in the above picture, there is an index for every key value in the data file in the dense index.
2. Sparse Index - Sparse Index points to a particular block in the data file. Unlike a dense index, there may not be index records for every key value in the data file. This is also the reason that it consumes less space than the dense index. It is slower than the dense index because every sparse index does not point directly to a particular record in the data file.
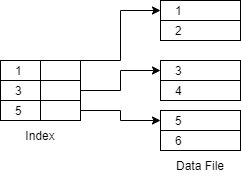
In the above picture shown for sparse index, there is an index record for very few key values in the data file.
Clustered Index
The clustered index can be used in the case of the ordered data file. The index is created on the record which is not unique in the data file by grouping those which have similar characteristics. The index key points to every block in which data can be found related to that index value.
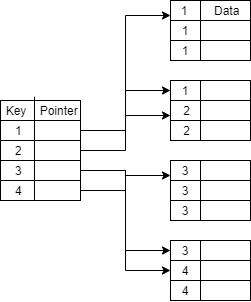
Non-Clustered Index or Secondary Index
The Secondary index or non-clustered index can be used to access the data which are not stored in the ordered form in the data file. The secondary index can be created on attributes other than the primary key. Each entry gives the location where the data is stored. The dense ordering is only possible in the non-clustered index as the data is not physically organized according to the index.
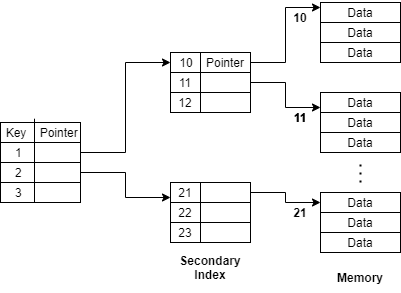
Multilevel Indexing
When the database becomes much bigger it becomes difficult to fit them in a single level of indexing. Multilevel indexing is done for the bigger databases. Indexing is done on various levels in multilevel indexing. Multilevel indexing helps in breaking down the index into similar multiple smaller indices so that the outermost and smallest index table can fit into the main memory.

As shown in the above picture, multilevel indexing has different layers of the index and the outermost layer is the smallest.

